Final project wiki
Objective
There are several performance bottlenecks in the lock manager of Innodb storage engine, which is the default in mariadb 10.2. Innodb’s lock manager is the first bottleneck, aiming to improve the performance of mariadb by making this part scalable.

This project is divided into two major milestones.
- Milestone 1: Resolve performance bottlenecks of read-only transaction (due date: Dec 6, 2017)
- Milestone 2: Resolve performance bottlenecks of read/write transaction (due date: Dec 24, 2017)
Analysis of lock manager
Milestone 1
Milestone 1 resolve performance bottlenecks of read-only transaction. Describe the process through how resolve the bottleneck below.
Implementation of milestone 1 can not guarantee the correctness of the write operation. Therefore, when you run a test using sysbench, prepare process is safe to run before changes to this project.
The reality of the bottleneck
See Image 2, Perf record of base model and Image 3, Perf record of enhanced model in bottom of page.
You can check rate of PolicyMutex close to 50%. However, it can not be seen in the improved version..
Process
The Process of read operation is as follow. (The innobase on the left and right is my implementation.)
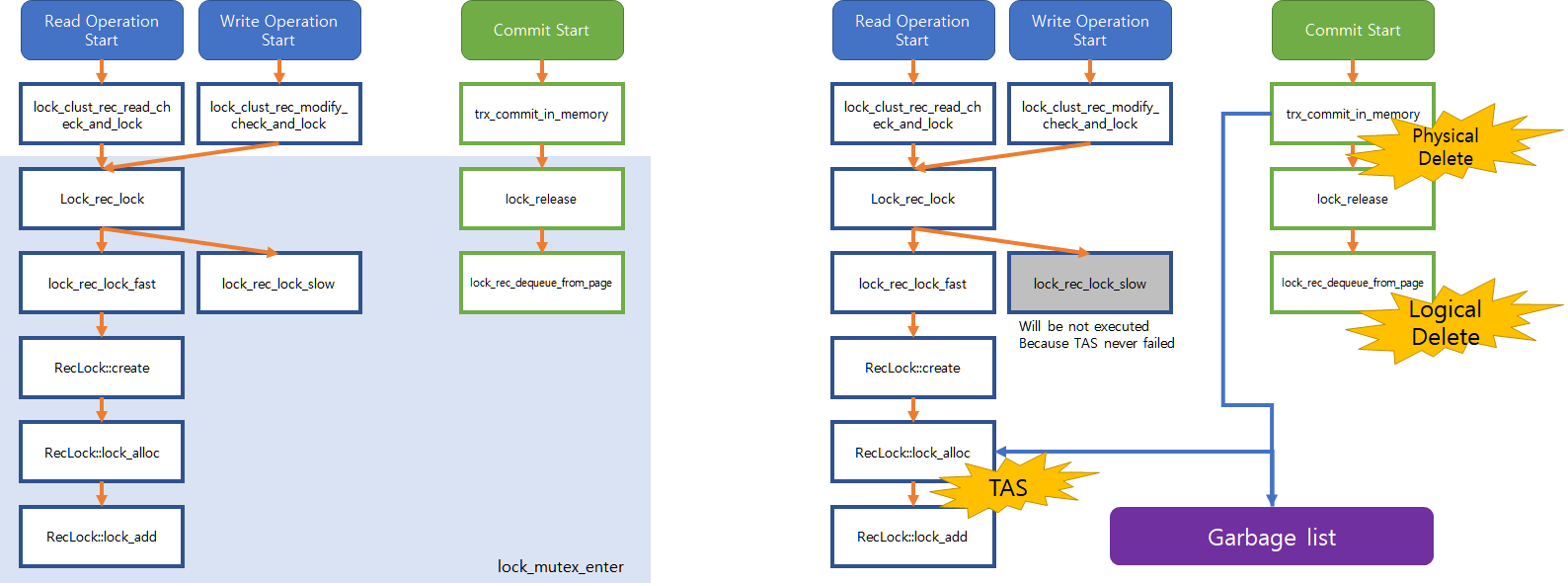
Figure 1. Innobase workload structure
Solution
In order to solve the performance degradation caused by global lock, the lock for the record is managed as a lock-free linked list.
My solution is separated by macros. See block of #ifdef ITE4065 to #endif.
Lock Insertion
Requests coming in by read-only workload call lock_rec_lock via lock_clust_rec_read_check_and_lock function(see Figure 1). The original design is to hold the lock before lock_rec_lock and release it after acquire lock. However, to avoid that locking, change the root to point lock_rec_lock to the lock insert in the lock-free list.
Optional: implemented a generic lock-free linked list for testing.
In the modified implementation, it is executed according to the following function call.
lock_clust_rec_read_check_and_locklock_rec_locklock_rec_lock_fastRecLock::createRecLock::lock_alloc,RecLock::lock_addlock_rec_insert_to_tail
First of all, RecLock::lock_alloc uses ut_malloc_nokey to allocate and initialize memory for lock_t*.
In RecLock::lock_add, call lock_rec_insert_to_tail to append lock to lock-free list and add to trx_locks.
lock_rec_insert_to_tail is main implementation of latch-free design, using lock-free list to append new lock to tail of list. This process is handled using __sync_lock_test_and_set changes the hash of the previous node to point to current node. In case of tail of list is null, this means head is empty, so change head to point to current node. Order is guaranteed even if tail changes are requested by multiple threads because test_and_set(__sync_lock_test_and_set) is atomic operation and serialize contention.
Lock Deletion
When a commit query comes in, the locks released by the transaction are released. If release lock immediately, Other threads that hold the lock can cause problems especially race. So, using logical deletion and physical deletion separately.
logical deletion is changing state of lock to false which owner of the lock wants to release. And searching node in list of lock to detach logically deleted lock from list. If find the marked(logically deleted) node, using compare_and_swap(__sync_bool_compare_and_swap) to change node’s hash pointing to next. So, other thread can not read the marked node even if contention. If compare_and_swap is successed, change next node’s stamp to global timestamp. global timestamp guarantee that bigger than running transactions stamp.
Since timestamp can be used in all transactions, it is managed by trx_sys and incremented by fetch_and_add(__sync_fetch_and_add) every time each commit.
Garbage Collection
Even if performed logically deletion to lock, can’t guarantee all of other threads not holding the deleted lock. That is why using logical deletion and physical deletion separately. Logical deletion just marking the node to say “This node will be released!” and detach node from lock list, attach to garbage collection list. In attach to garbage collection list using compare_and_set prevent race condition.
physical deletion is performed by the victim thread. Victim find timestamp which has minimum timestamp in running transactions and release lock iterating garbage collection list which timestamp is lower than minimum timestamp. Victim can wait with spinning if tail is changed while changing pointer of node. Especially tail is not pointing current node and next node’s hash is null it’s mean other thread change tail before changing pointer. check gc_hash and lock0lock.cc:3281 on lock_t.
This implementation is not very good for performance, As the number of nodes to be deleted increases, the victim thread waits for garbage collection to increase significantly. This can be solved by creating a special thread for garbage collection. However, I have not implemented it because can not specifically determine the execution or end time of a specific thread in the current situation without affecting other tasks,.
Object Pool
There is several implementation for object pool, but this is not fully implemented. The implemented lock allocation will be used to steal the lock from garbage collector that the transaction is ended when a new lock allocation is requested. The timestamp value confirms that the transaction has ended.
This object pool has not unrestricted size and it has an inefficient aspect in that deletion must occur before the allocation.
Milestone 2
Most processes that are compatible with Milestone 1’s operation will operate the same latch-free. The write operation is called through the lock_clust_rec_modify_check_and_lock function, and the lock_rec_lock is called again, so the read operation in Milestone 1 is designed as latch-free and the write operation is executed with the same latch-free logic.(See Figure 1)
I ran the sysbench test to write to it, but it was not a problem.
But this is not clear and I am expecting that someday it’ll get an error. (but not now… and this makes me difficult to debug.)
Design
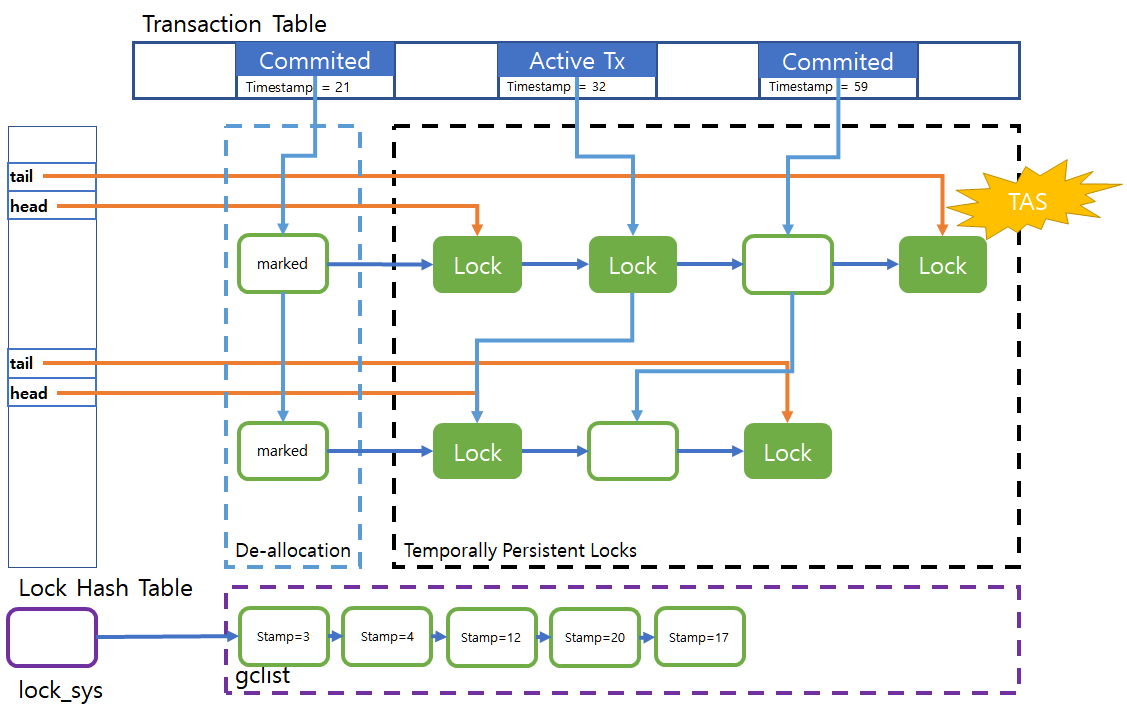
Figure 2. Whole design
Problem
There are some problem in this design. In my design it takes a very long time because one victim performs all the physical deletions.
Furthermore, the latch-free design is not using innobase allocation method, so it is not properly monitored. This can cause a big problem for the whole system. The most important issue is that if you try to force mysqld to shut down before all of the physical deletes are done, mysql will detect that the memory has not been emptied and may cause an error.
This problem can be solved by putting an exception in the assertion process of mysql before shutdown or using supported utility to allocation in latch-free design.
So when you test this project yourself, you should give a lot of time after test and before exiting mysql.
Results
Test on Linux System using sysbench
Ubuntu 14.04.5 LTS
- Intel(R) Xeon(R) CPU E5-2650 v2 @ 2.60GHz (with 32vCPU)
- Intel(R) Xeon(R) CPU E5-2680 v2 @ 2.80GHz (with 32vCPU)
- Intel(R) Xeon(R) CPU E5-2666 v3 @ 2.60GHz (with 36 vCPU)
Sysbench 1.0.10
you can check the original result log on project4/results.
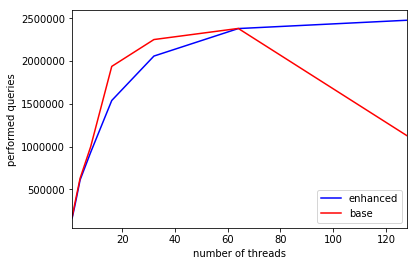
Image 1, Test result
And you can compare perf log between base and enhanced model.
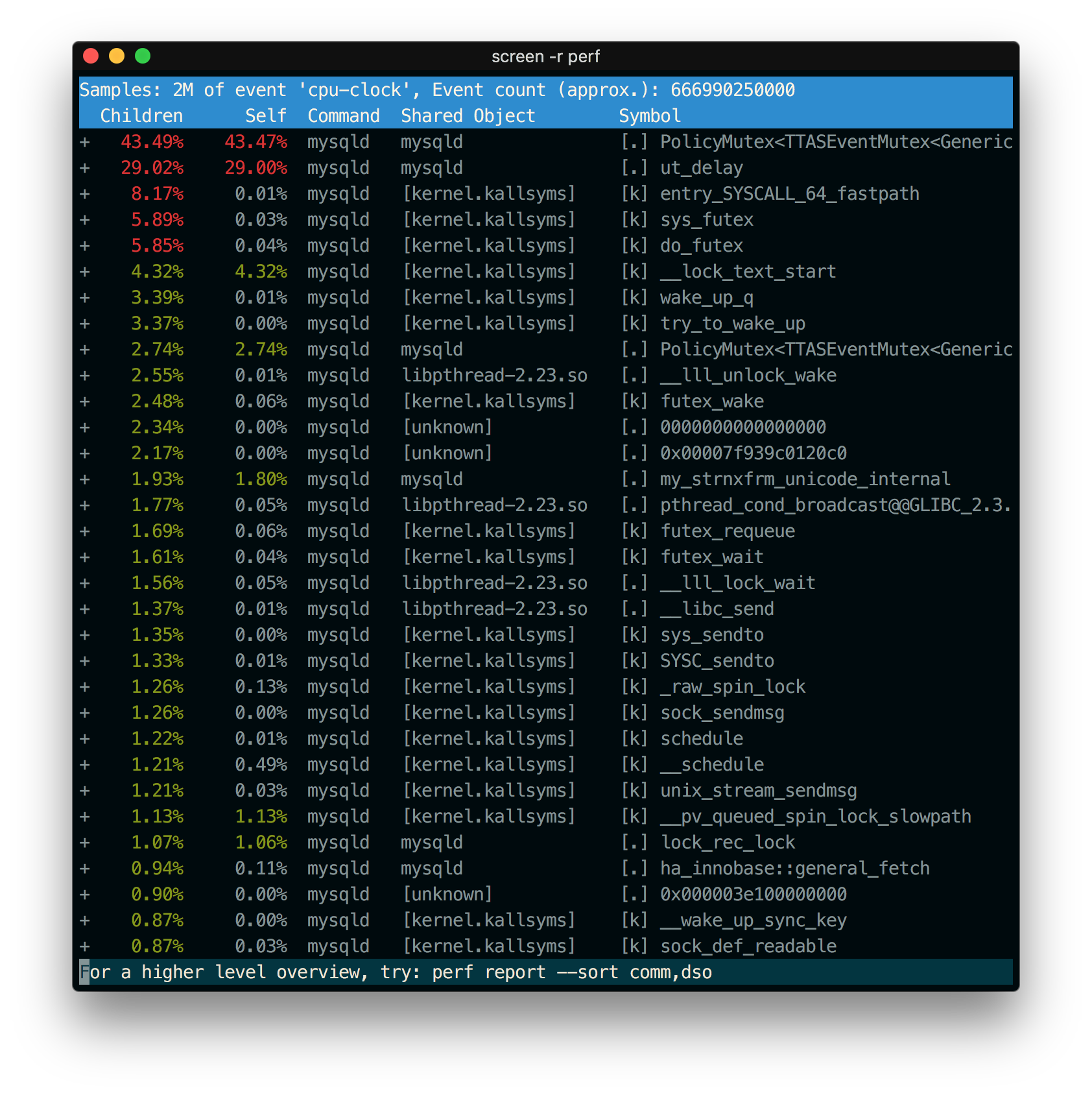
Image 2, Perf record of base model
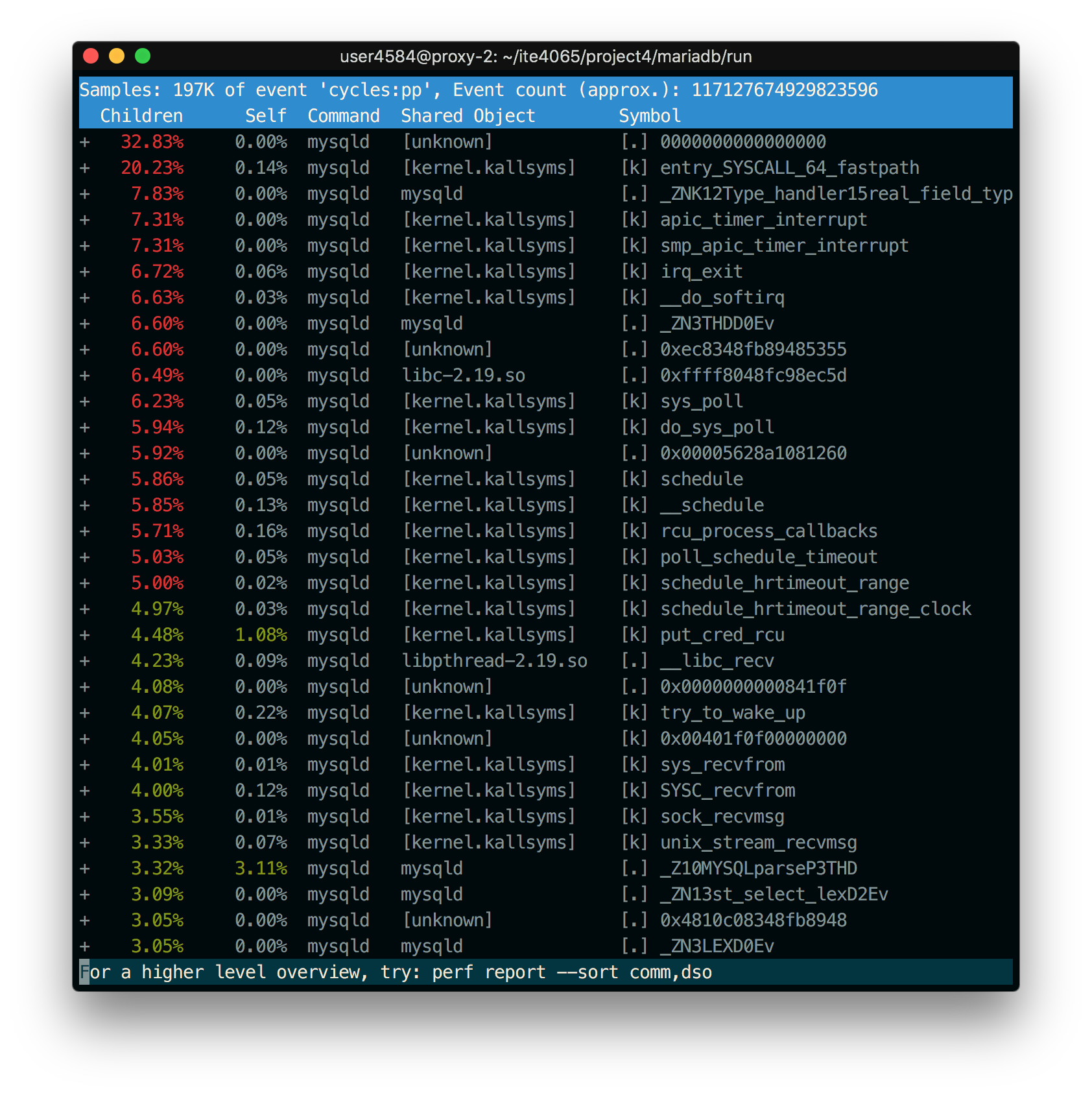
Image 3, Perf record of enhanced model